Data Pipeline: The Backbone of Data-Driven Organizations






In today’s data-driven world, organizations increasingly rely on data pipelines to streamline the flow of information and ensure accurate analysis. A robust data pipeline is crucial for collecting, processing, and analyzing large amounts of varied data from various sources in real time. In this blog post, we’ll explore what a data pipeline is, why it’s essential for businesses of all sizes, and the challenges while building one. Then, we will share some best practices for maintaining your Data Pipeline over time.
What is a Data Pipeline?
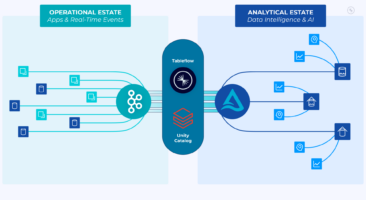
A data pipeline is a series of processes that extract, transform, and load (ETL) data from various sources into a destination system for analysis. The purpose of the pipeline is to ensure that data flows seamlessly and securely from source to destination while undergoing any necessary transformations along the way.
The components of a data pipeline typically include source systems such as databases or APIs, an ETL tool for transformation, and a destination system such as a database or analytical platform. Key features of an effective data pipeline include scalability, reliability, fault tolerance, and efficient use of resources. Organizations can efficiently manage their complex data environments by implementing well-designed data pipelines to drive insights and improve decision-making capabilities.
Definition
A data pipeline is a system that enables organizations to efficiently move and transform raw data from various sources into usable formats that can support business decision-making. The role of a well-designed data pipeline in an organization cannot be overemphasized, as it ensures the accuracy, reliability, and timeliness of data used for analysis.
A well-designed data pipeline ensures accurate and reliable data for business decision-making.
A data pipeline is defined by the following characteristics: scalability, fault tolerance, security features as well as ease of use, and maintenance. A well-architected pipeline should also allow for easy integration with different sources while maintaining standards for quality control throughout the transformation process.
Components
A data pipeline is an essential backbone of data-driven organizations, and it consists of various components that work together to move and process large volumes of data. One critical component is the Data Sources and Integration Points that gather information from different sources such as databases, APIs, or streaming platforms. The source data can then be filtered, cleaned, and integrated into a single pipeline for further processing.
Another crucial component is the Data Storage and Management Systems responsible for securely storing all incoming data. These systems ensure easy access to stored information while maintaining its quality through backups in case of loss or corruption. Lastly, Data Processing and Transformation Tools are used to manipulate raw data into meaningful insights by applying transformations like filtering out irrelevant entries or aggregating related pieces of information. These tools streamline the extraction process while maintaining accuracy in results through efficient transformation processes within the pipeline system.
Key features
Scalability and flexibility are essential features of a modern data pipeline. The ability to handle large volumes of data while maintaining efficiency is crucial for organizations that rely on data-driven decision-making. Moreover, the robustness and reliability of the pipeline must ensure consistency in processed data outputs regardless of changes in sources or transformations.
Efficient monitoring, debugging, error handling, and reporting capabilities are also critical features. With these capabilities integrated into the pipeline’s design, any issues can be addressed quickly to minimize downtime. Additionally, monitoring allows organizations to make informed decisions about optimizing their processes for better performance in real time.
Why are Data Pipelines important?
Data pipelines are crucial for data-driven organizations as they enable seamless data flow from various sources to their destinations. They automate the process of collecting, processing and transforming raw data into valuable insights that can be used for decision-making purposes. Data pipelines also improve productivity and efficiency by reducing manual labor and ensuring the timely delivery of accurate information.
The accuracy and quality of data play a significant role in making informed decisions. Data pipelines ensure that only clean, reliable, and consistent data enters an organization’s systems. This is achieved through automated validation checks, error-handling mechanisms, and duplicate removal protocols. The result is trustworthy information that stakeholders can rely on to make better-informed decisions quickly.
Data-driven decision making
Real-time data availability, consistency, and reliability of data are crucial for successful data-driven decision-making. Organizations must have access to accurate and trustworthy data on time to inform strategic choices. Additionally, analyzing large volumes of data is essential for gaining insights that may not be immediately apparent from smaller datasets.
To ensure effective decision-making based on your organization’s available information, consider the following:
- Utilize real-time monitoring tools to capture current trends or changes in customer behavior
- Establish standards for maintaining consistent and reliable data across all departments
- Implement scalable infrastructure capable of handling large amounts of both structured and unstructured data
Data-driven organizations recognize the importance of robust pipelines that can effectively collect, process, store, and analyze their incoming data. To make informed decisions quickly while staying ahead of competitors striving towards the same goal, your company must invest time into building an optimal Data Pipeline.
Productivity and efficiency
Automated processes can significantly improve productivity and efficiency in data pipelines. By automating repetitive tasks such as data entry, cleaning, and transformation, teams can focus on more strategic activities that require human attention. It speeds up the process and reduces manual, error-prone tasks that could lead to inaccuracies in data.
Eliminating redundant work is also critical for maximizing productivity and reducing costs associated with wasted time and resources. By streamlining the pipeline through automation, organizations can identify areas where duplication occurs or unnecessary steps are taken. Removing these redundancies frees up time and resources that can be redirected toward higher-value activities like analysis or innovation.
Data quality and accuracy
Validation checks on incoming data sources are crucial to ensure the accuracy and completeness of the data. Automated validation checks can flag anomalies or inconsistencies in real-time, allowing for quick corrective action. Additionally, cleansing, enrichment, and transformation of raw data help address any missing or incorrect information issues. It helps to improve overall data quality and reduces errors that could lead to inaccurate reporting.
Integration with existing systems is essential for accurate reporting. Poorly integrated systems can result in duplicate or incomplete records that affect the quality of downstream analytics applications. Organizations can leverage accurate insights from their datasets by ensuring seamless integration between various platforms involved in a company’s workflow processes. This increases confidence levels in decision-making processes based on high-quality intelligence derived from an efficient and reliable data pipeline system.
How to build a Data Pipeline?
To build a data pipeline:
- Start by identifying your data’s source(s) and defining the desired output.
- Develop a clear understanding of how each pipeline stage will manipulate and transform the data as it flows through.
- From there, design and implement each component using appropriate technologies.
When choosing your technology stack for a data pipeline, consider scalability, flexibility, reliability, and cost-effectiveness factors. Popular options include:
- Kafka for messaging queues, Spark for processing large datasets in real-time or batch mode depending on requirements
- AWS services(Lambda, Step Functions, Glue), Airflow, or Luigi to orchestrate workflows
- File storage as AWS S3, data warehouse such as AWS Redshift or Snowflake, databases like PostgreSQL or MongoDB for storage
By following these steps to build a robust data pipeline with an effective technology stack that meets your organization’s needs, you can efficiently handle massive volumes of information while maintaining the high-quality levels required to make informed business decisions.
Choosing the right technology stack
Assessing data volume and velocity requirements are crucial when choosing the right technology stack for your data pipeline. You want to ensure that the technologies you choose can handle the amount of data you expect to process and at the speed necessary for timely insights.
When evaluating the scalability and flexibility of technologies, consider whether they can grow with your organization’s needs and adapt to new use cases without requiring a complete overhaul of your system. Additionally, it’s essential to consider security, compliance, and governance needs as they play a critical role in ensuring that data is handled appropriately.
Some key factors to keep in mind when selecting a technology stack for your data pipeline include:
- The ability to scale up or down quickly based on changing business needs
- Compatibility with existing systems
- Support for real-time processing if necessary
- Availability of reliable documentation and community support
Challenges in building and maintaining Data Pipelines
Building and maintaining data pipelines come with multiple challenges that must be addressed. One of the biggest concerns is ensuring data security and privacy during transmission, storage, and processing. It includes managing access controls, encrypting sensitive information, detecting potential threats or breaches, and complying with regulations such as GDPR or HIPAA.
Another significant challenge in constructing a robust data pipeline is achieving seamless integration and synchronization between various data sources. It requires implementing standard protocols for communication among multiple components while supporting diverse formats of input/output. Keeping all the source systems constantly up-to-date can also prove tricky when dealing with large amounts of heterogeneous datasets across different platforms.
Data security and privacy
Data security and privacy are critical components of any data pipeline. To safeguard sensitive information from unauthorized access, encryption methods must be employed for data in transit and at rest. Access control measures should also ensure that only authorized personnel can access such information.
Moreover, anonymization techniques are essential to protect individual identities while preserving the data’s usefulness. By removing personally identifiable information (PII), organizations can prevent potential breaches and maintain compliance with regulatory requirements. Overall, robust security measures are necessary to build trust with stakeholders and enable successful data-driven decision-making within an organization’s pipeline.
Data integration and synchronization
Ensuring compatibility between different sources of data is crucial in any data pipeline. Integrating various types of data can be a complex process, but it’s essential to ensure that all sources are compatible and can work together seamlessly. It requires careful planning and attention to detail to avoid any potential issues down the line. Establishing a data catalog for managing metadata for data sources is recommended.
Real-time synchronization is also essential for avoiding discrepancies or delays in reporting. Real-time synchronization instantly reflects all data updates across all connected systems and applications. It ensures that everyone can access accurate and up-to-date data at all times.
Dealing with missing or incomplete datasets can also be challenging when integrating different data sources into your pipeline. It’s essential to have processes to identify these gaps so they can be filled as soon as possible through manual entry or automated methods such as machine learning algorithms. By addressing these issues early on, you’ll ensure that your organization has complete and accurate information for making informed decisions.
Data scalability and performance
Building a data pipeline that can handle increasing volumes of data over time is crucial for organizations to stay competitive in today’s fast-paced business environment. However, scaling up the data pipeline without sacrificing speed or accuracy can be challenging. Here are some ways to ensure scalability and performance while maintaining accuracy:
- Using distributed computing technologies like Hadoop or Spark for parallel processing capabilities
- Implementing automation tools and techniques to reduce manual intervention
- Monitoring pipeline performance, identifying bottlenecks, and executing optimizations as needed
By implementing these strategies, organizations can build flexible and scalable data pipelines that meet their evolving needs.
Best practices for Data Pipeline maintenance
Effective data pipeline maintenance ensures smooth and seamless data flow within an organization. It’s essential to monitor and log the performance of your pipelines regularly. This allows you to quickly identify and proactively address any issues before they become significant problems.
Another best practice for maintaining your data pipeline is testing and validation. Regularly testing your data pipelines ensures that they are functioning as intended, while validation helps ensure the accuracy of the data being transferred through them. By implementing these practices, organizations can improve their efficiency and effectiveness in utilizing their valuable data resources.
Monitoring and logging
Setting up alerts and notifications for failures is crucial in ensuring your data pipeline runs smoothly. It enables you to detect issues immediately, allowing you to take immediate action and prevent data loss or corruption. Tracking metrics such as latency, throughput, and error rates gives insight into the system’s overall health. Monitoring these key performance indicators can help identify trends or potential bottlenecks before they become critical.
Logging all pipeline activities is vital in enabling troubleshooting when things go wrong. By capturing every step taken within the data pipeline, developers can quickly trace issues back to their source, saving valuable time during incident resolution. Having access to detailed logs also makes it easier for teams to collaborate on fixing complex problems by providing contextual information about what went wrong and how it occurred.
Testing and validation
Automated testing of data transformations is crucial in ensuring the accuracy and consistency of your data pipeline. By automating tests for each transformation step, you can quickly identify errors and improve the efficiency of your data pipeline. Additionally, validating input/output schema compatibility checks provides you with an added layer of protection against potential errors that could affect downstream processes.
Verifying data quality at each stage of the pipeline helps to ensure consistency and accuracy throughout the process. It includes checking for completeness, validity, uniqueness, and consistency across all tables involved in the data pipeline. By monitoring these factors at every stage, you can catch any inconsistencies or inaccuracies early on before they become more significant issues down the line.
Overall, thorough testing and validation are integral to successful data pipeline implementation. Implementing automated testing procedures for transformations and schema compatibility checks while verifying high-quality data at each stage of the process ensures a smooth flow from start to finish while providing actionable insights along the way to keep improving it further over time.
Documentation and communication
Creating clear documentation and establishing effective communication channels are crucial for successfully implementing and maintaining a data pipeline. Regular meetings with stakeholders ensure that updates or changes in the pipeline are communicated effectively and potential issues can be addressed promptly. A communication plan should also be established to handle incidents or anomalies within the data pipeline.
Key points:
- Clear documentation on how the data pipeline works
- Scheduled meetings with stakeholders to communicate updates/changes
- Establishing a communication plan for handling incidents/issues
Conclusion
In conclusion, a well-designed and properly maintained data pipeline is essential for any organization looking to make data-driven decisions. The pipeline provides a mechanism for ingesting, processing, storing and analyzing data at scale while ensuring its quality and security. Without it, organizations would struggle with manual processes that are error-prone and slow.
Moreover, in today’s competitive market where data is the new currency of success, having an efficient data pipeline can give organizations a significant advantage over their competitors. It allows them to leverage the insights hidden within their vast amounts of raw information quickly and accurately. Hence investing time in creating or upgrading the existing pipeline should be a top priority for businesses aiming to become truly data-driven institutions.
LoadSys Solutions
LoadSys Solutions understands the importance of a data-driven architecture in today’s fast-paced business environment. Businesses can make quicker and more informed decisions by reducing data silos and streamlining processes through automated integration.
At LoadSys Solutions, we pride ourselves on our experience in creating solutions that leverage the power of a data-driven architecture. So let us help you unlock the full potential of your organization’s valuable asset – its data.