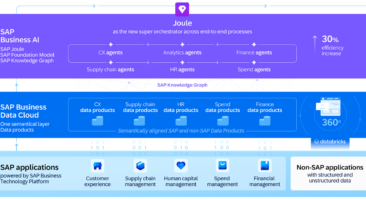
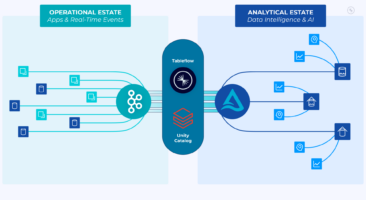
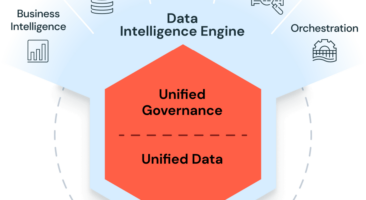
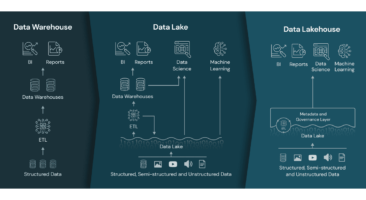
Data Mesh: Transforming the Way We Approach Data Management






What is data mesh?
Data mesh is a new architectural approach to data management that aims to improve the scalability and efficiency of data systems. In traditional data management, data is typically centralized, which can create bottlenecks and hinder the ability to process and analyze large volumes of data quickly.
Data mesh, on the other hand, distributes data ownership and management across different teams or domains within an organization. Each domain is responsible for managing its data, which is then shared and integrated with other domains through well-defined APIs, protocols, and self-serve platforms.
This approach has several benefits, including improved agility, scalability, and flexibility. By allowing each domain to manage its data, organizations can better align data with business processes and requirements and speed up the time-to-value for data-driven initiatives. Additionally, by breaking down data silos and enabling cross-domain collaboration, data mesh can foster a culture of data-driven decision-making and innovation.
Organizations need to invest in robust data integration and governance solutions that can seamlessly connect and manage data across distributed domains to implement a data mesh architecture. Process automation tools can also streamline data workflows and ensure data quality and consistency across the entire ecosystem.
Data mesh is a promising new approach to data management that can help organizations unlock the full potential of their data assets and drive business growth and innovation.
What are the key features of data mesh?
Data mesh is an approach to managing data that has been gaining popularity in recent years. It is a way of organizing data that emphasizes decentralization and autonomy, allowing individual teams to manage their own data domains independently. Here are some key features of the data mesh approach:
1. Domain-oriented architecture: Data mesh is built around the concept of domains, which are self-contained units of data that are owned and managed by individual teams. Each domain is responsible for its own data quality, governance, and security.
2. Decentralized data ownership: Under the data mesh approach, the ownership of data is decentralized, with individual teams responsible for managing their own data domains. This allows for greater agility and flexibility in responding to changing business needs.
3. Data as a product: In the data mesh model, data is treated as a product that is created and consumed by different teams within the organization. This shifts the focus from technology to business outcomes and helps to ensure that data is aligned with the needs of the organization.
4. Self-Serve Data Platform: One of the key principles of data mesh is the self-serve data platform. This involves providing teams with the tools and resources they need to manage their own data domains, including data integration, governance, and quality control. By allowing teams to access and analyze data independently, a self-serve data platform can help to speed up data-driven decision-making and improve overall business agility. At the same time, it can help to ensure that data is managed consistently and securely across the entire organization, regardless of which team is responsible for it.
5. Data governance and quality: Data mesh emphasizes the importance of data governance and quality, with each domain responsible for ensuring that its data meets the organization’s standards for accuracy, completeness, and consistency.
6. Automation and orchestration: Automation and orchestration play a crucial role in enabling efficient data integration and processing in a data mesh architecture. By automating repetitive tasks and orchestrating data workflows, businesses can streamline their data operations and improve overall efficiency and agility.
How does data mesh differ from traditional data architecture?
In traditional data architecture, data is typically organized and managed in a centralized manner, with a focus on standardization and control.
On the other hand, data mesh is a decentralized approach to data architecture that emphasizes domain-specific data ownership and management. In a data mesh architecture, data is organized around business domains, each responsible for managing its data and making it available to other domains as needed.
Unlike traditional data architecture, data mesh allows for greater flexibility and agility, as each domain can make its own decisions about managing its data and integrating it with other domains. This approach also allows for greater scalability, allowing organizations to add or remove domains as needed to meet changing business needs.
Another essential difference between data mesh and traditional data architecture is the role of technology. In traditional data architecture, technology is often seen as the solution to data management challenges, focusing on selecting and implementing the right tools and platforms. In contrast, data mesh emphasizes collaboration and communication between business and technical teams, focusing on developing shared understanding and processes for managing data.
Overall, data mesh represents a significant departure from traditional data architecture approaches, offering a more flexible, decentralized approach to data management that is better suited to the needs of modern, data-driven organizations.
What are the benefits of data mesh?
Data mesh is a relatively new approach to data architecture that has recently gained popularity. It is based on the concept of decentralization, which means that each team within an organization is responsible for managing its own data. This approach has several benefits, making it an attractive option for IT decision-makers seeking data warehouses, data integration, and process automation solutions.
1. Scalability: The decentralized nature of data mesh makes it highly scalable. Each team can manage its own data and scale its infrastructure independently of others. Organizations can easily add new teams and data sources without disrupting existing workflows.
2. Flexibility: Data mesh also offers flexibility regarding technology and tools. Teams can choose the tools and technology that work best for their specific data needs rather than being constrained by a one-size-fits-all approach.
3. Faster Time to Market: With data mesh, teams can deliver data products and services faster because they have ownership and control over their data. This allows teams to make decisions and iterate quickly without waiting for approvals from other departments.
4. Better Data Quality: Each team is responsible for the quality of its own data, which encourages a culture of data ownership and accountability. It leads to better data quality and trust, essential for making data-driven decisions.
5. Improved Collaboration: Data mesh encourages team collaboration, as it requires communication and coordination to ensure that data is shared and integrated effectively.
Overall, data mesh offers a more flexible, scalable, and decentralized approach to data management that allows organizations better to meet the needs of their business and customers. Organizations can create a culture of data ownership and accountability by giving each team ownership and control over their data, leading to better data quality and faster time-to-market for data products and services. Additionally, the flexibility and scalability of data mesh allow organizations to easily add new teams and data sources as needed without disrupting existing workflows. For IT decision-makers seeking data warehouse, data integration, and process automation solutions, data mesh is a compelling option that should be seriously considered.
How does data mesh help organizations manage their data?
Data mesh is a modern approach to managing complex data ecosystems that are becoming increasingly common in organizations today. It is a framework for organizing data into smaller, more manageable pieces that can be easily shared and reused across different teams and departments.
One of the key benefits of data mesh is that it enables organizations to better manage their data by breaking down silos and reducing dependencies between different teams and systems. Organizations can improve decision-making, reduce errors, and improve overall productivity by providing a more cohesive, integrated view of data.
Another advantage of data mesh is that it promotes greater scalability and flexibility, allowing organizations to scale up or down their data infrastructure as needed quickly. It can be particularly valuable for organizations that need to adapt swiftly to changing market conditions or customer needs.
Finally, data mesh also supports better data governance and compliance by providing a more structured, standardized approach to data management. It can help organizations to manage better risks related to data security and privacy, as well as ensure compliance with various regulatory requirements.
Overall, data mesh provides a modern, flexible, and scalable approach to managing data that can help organizations to improve productivity, reduce errors, and better manage risk. If you are an IT decision-maker looking for a data warehouse, data integration, or process automation solution, data mesh is a framework that should be on your radar.
How does data mesh help organizations scale their data?
Data mesh is a relatively new approach to organizing data within an organization. This methodology allows organizations to scale their data by decentralizing their data infrastructure, enabling individual teams to manage their own data domains.
Traditionally, data warehouses were designed to centralize data from various sources into a single repository for analysis and reporting. While this approach worked well for many years, it has limitations in today’s rapidly evolving data landscape. With the explosion of data sources and types, centralizing data in a single repository can become overwhelming and challenging to maintain.
The data mesh approach recognizes that data is not a single source of truth but a distributed asset in multiple locations within an organization. It focuses on creating a network of data domains, each with its own data product manager responsible for the quality, accessibility, and governance of the data within that domain.
Organizations can improve their scalability by adopting a data mesh approach by creating a more agile and decentralized data infrastructure. This approach allows for faster data access and analysis, improved data quality and governance, and more efficient use of resources. It also enables organizations to respond more quickly to changing business needs by providing more flexibility and agility in data management.
In summary, data mesh helps organizations scale their data by decentralizing their data infrastructure, enabling individual teams to manage their own data domains, and creating a more agile and responsive data management approach. This approach can help organizations to stay competitive in today’s data-driven business environment.
How does data mesh facilitate data governance?
Data mesh is a decentralized approach that prioritizes data autonomy and ownership, enabling individual teams to take responsibility for their data domains. This approach contrasts with traditional centralized data management, often resulting in data silos and bottlenecks.
One of the key benefits of data mesh is that it facilitates data governance. By giving teams ownership and responsibility over their own data domains, data mesh allows for more efficient and effective data governance. Rather than relying on a central data team to manage all data across the organization, data mesh enables each team to manage the most relevant data to their domain.
In addition, data mesh encourages using standardized data contracts, which can help ensure that data is consistent and reliable across the organization. These contracts specify how data should be structured, what it should contain, and how it should be accessed and used. By using standardized contracts, teams can ensure that their data is both accurate and easily understandable by other teams in the organization.
Data mesh can be a valuable tool for IT decision-makers seeking to improve their data governance practices. By decentralizing data management and encouraging ownership and standardization, data mesh enables more efficient and effective data governance across the organization.
What considerations should organizations take when implementing data mesh?
Data mesh has recently gained popularity as a new approach to organizing data within organizations. This approach emphasizes decentralization, data ownership, and the democratization of data. If you’re considering implementing data mesh in your organization, there are several factors to keep in mind. Here are the top considerations to keep in mind:
1. Cultural Shift: Data mesh requires a significant cultural shift. It is essential to ensure that everyone in the organization understands and is committed to the new philosophy of data mesh. The organization should be ready to adopt a culture that values data ownership, autonomy, and accountability.
2. Data Governance: Data mesh does not eliminate the need for governance. The organization must ensure a robust data governance framework for flexibility and autonomy within the data mesh architecture.
3. Data Mesh Architecture: The architecture for data mesh should be designed to allow for easy access to data, with clear boundaries and domains. This architecture should be scalable and flexible enough to accommodate changing needs and requirements.
4. Tooling: Organizations implementing data mesh should use the proper tooling to support the approach. This may include tools for data management, data integration, and process automation.
5. Skills: The organization must have the right skills to implement and manage data mesh. It includes data engineers, data scientists, and other IT professionals with the necessary technical expertise.
6. Communication: Effective communication is critical to the success of data mesh. The organization must ensure that everyone involved in the process is informed and aligned on the goals and objectives of data mesh, as well as their roles and responsibilities.
In conclusion, implementing data mesh requires a significant cultural shift, a robust data governance framework, and the right architecture, tools, skills, and communication. Organizations can successfully implement data mesh and improve their data governance practices by considering these factors and taking a methodical approach. As IT decision-makers, staying informed and knowledgeable about emerging data management approaches like data mesh is essential to ensure that your organization remains competitive and efficient in today’s data-driven business environment.
How can organizations integrate data mesh into their existing infrastructure?
If you’re an IT decision-maker seeking to integrate data mesh into your existing infrastructure, here are some steps to consider:
1. Define your data domains: The first step in implementing data mesh is to identify the different domains within your organization. It could include customer data, product data, financial data, and so on. Each domain should have a clear owner and be responsible for managing the data within that domain.
2. Establish a self-serve platform: Once you have identified your data domains, the next step is establishing a self-serve platform for each domain. These platforms should be designed to provide access to the data within the domain and enable seamless data integration with other domains. The platform streamlines data product discovery and access.
3. Create data products: Data products are a crucial component of data mesh. They are self-contained functionality that provides business value by leveraging data from one or more domains. To create a data product, you must define its requirements, identify the data sources, and develop the necessary data pipelines.
4. Implement data governance: Data mesh requires a robust framework to ensure data quality, security, and compliance. This framework should include policies, standards, and procedures for data management across domains.
5. Invest in data infrastructure: To support data mesh, organizations must invest in a robust data infrastructure, which is crucial when building a data mesh. It requires a strong foundation of data warehousing, data integration, and process automation capabilities to enable the seamless flow of data across various domains and teams.
Conclusion
In conclusion, implementing data mesh requires a significant shift in how organizations manage their data. However, the benefits of a more scalable, decentralized, and collaborative approach to data management can be significant. By following the steps outlined above, IT decision-makers can effectively integrate data mesh into their existing infrastructure and reap the rewards of a more efficient and effective data ecosystem. It is important to note that successfully implementing data mesh requires technical expertise and effective communication across the organization. With the right team and approach, data mesh can transform the way organizations manage and leverage data, leading to better decision-making and improved business outcomes.