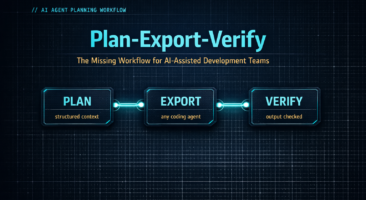
From Prompts to Pipelines: Operationalizing Context Engineering





Context engineering has emerged as a critical discipline for teams adopting AI-assisted development. While many organizations now recognize that prompt engineering alone cannot deliver consistent results, far fewer have figured out how to operationalize context engineering in a way that scales across teams and projects.
In practice, context engineering often begins as a set of good intentions. Teams know they should provide better requirements, clarify architecture, and share constraints. But without structure, these efforts remain manual and inconsistent. Over time, context degrades, accuracy stalls, and AI-assisted workflows lose trust.
This article explores how teams can move from ad-hoc prompts to durable pipelines—operationalizing context engineering so that AI coding accuracy improves predictably rather than sporadically.
Why Context Engineering Breaks Down in Real Teams
Most teams do not fail at context engineering because they disagree with its importance. They fail because ownership of context is unclear. Requirements live in task management systems, architecture lives in diagrams that may or may not be current, and critical constraints exist only in the heads of senior engineers.
When AI coding agents are introduced into this environment, they inherit the same fragmentation. Each interaction becomes an attempt to reconstruct understanding from partial information. The result is inconsistency, guesswork, and frequent rework.
Without a defined process, context engineering becomes dependent on individual effort. Different developers provide different levels of detail. Prompts vary widely. Accuracy becomes unpredictable.
The Limits of Prompt-Centered Workflows
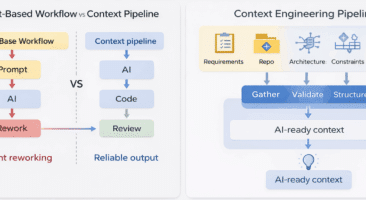
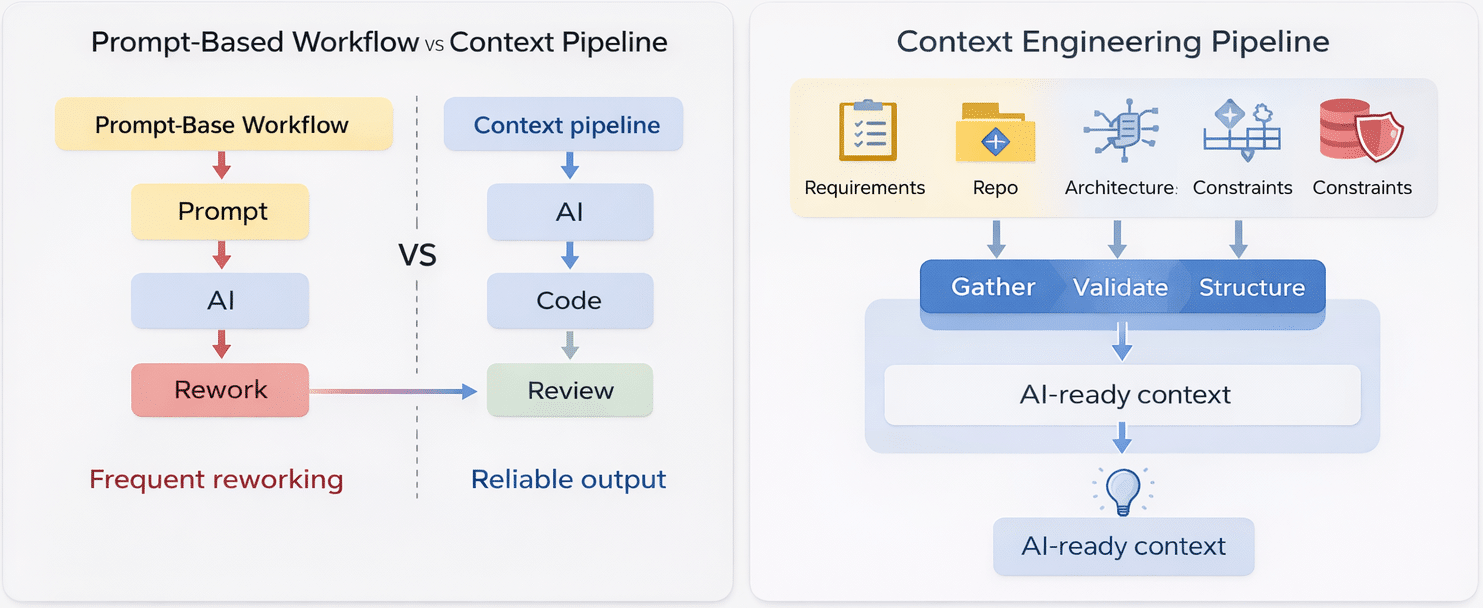
Prompt engineering treats context as something that can be compressed into a single instruction. This approach works reasonably well for small, isolated tasks where the scope is narrow and dependencies are minimal.
However, real-world software systems are not narrow. They span multiple services, data stores, frameworks, and deployment environments. They encode years of architectural decisions that are difficult to summarize in text.
As prompts grow longer, they become brittle. They are hard to maintain, easy to misuse, and difficult to validate. Teams often reuse prompts long after the system has changed, introducing subtle errors.
Eventually, teams hit a ceiling. Adding more detail to prompts stops improving AI coding accuracy because the underlying problem is not instruction quality—it is missing system understanding.
From Prompts to Pipelines
Operationalizing context engineering requires a fundamental shift in mindset. Instead of treating prompts as the primary interface with AI, teams must treat context as a structured input pipeline.
Pipelines introduce repeatability and consistency. Context is gathered, validated, and reused across sessions rather than recreated each time an AI coding agent is invoked.
This shift reduces cognitive load on developers and project managers. Instead of remembering what to include in a prompt, teams rely on a process that ensures the right information is always present.
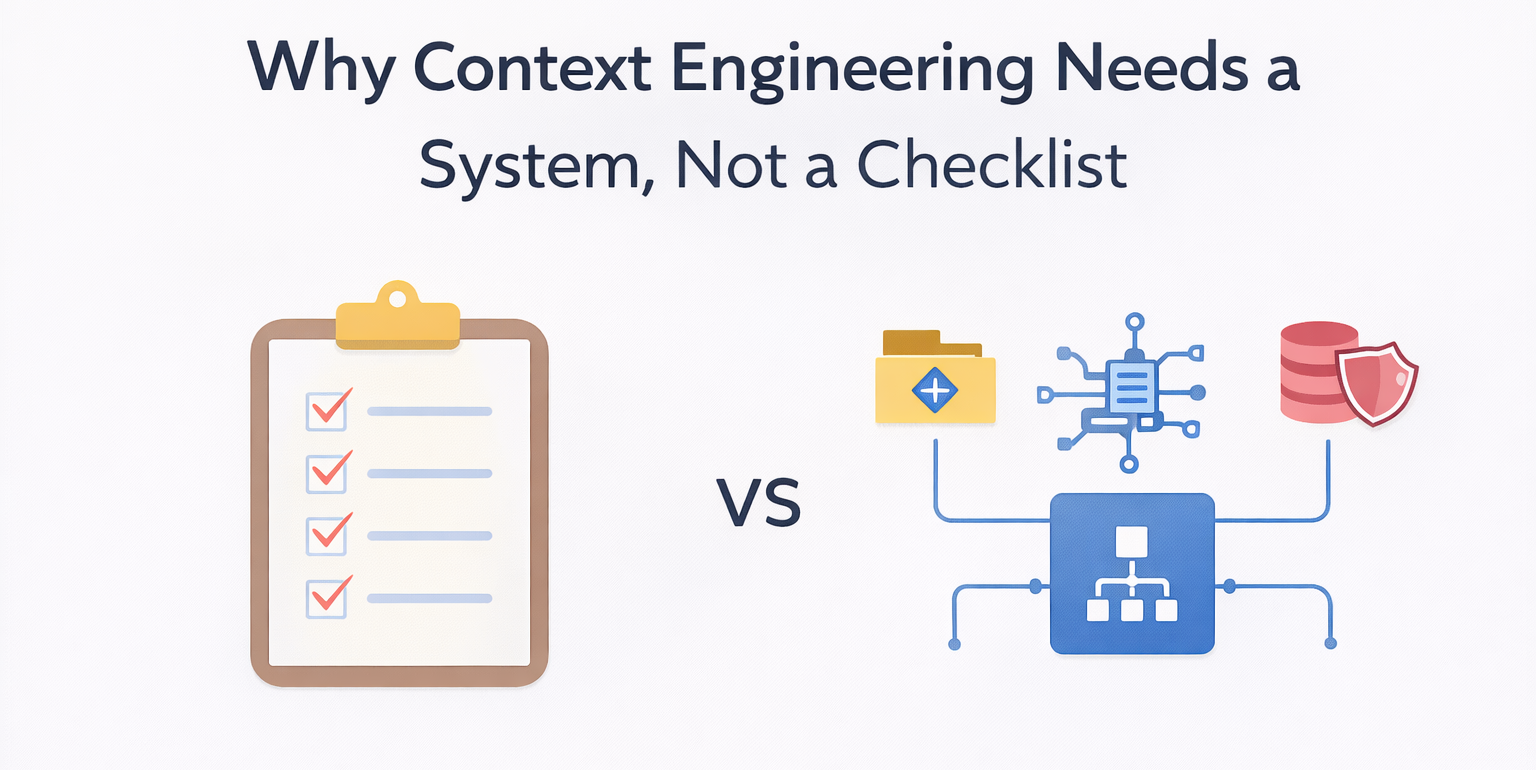
What a Context Engineering Pipeline Includes
Effective context engineering pipelines assemble multiple sources of truth into a cohesive whole. This includes functional requirements, acceptance criteria, architectural constraints, relevant code paths, dependencies, and non-functional requirements such as performance or security.
Importantly, pipelines also include validation steps. Assumptions are checked. Conflicts are surfaced early. Missing information is identified before code generation begins.
By front-loading this work, teams eliminate ambiguity and reduce the likelihood that AI coding agents will make incorrect assumptions.
Why Manual Context Does Not Scale
Manual approaches to context engineering rely heavily on human discipline. Developers must remember to update documents, revise prompts, and communicate changes. Over time, this discipline erodes.
As systems evolve, documentation drifts out of date. Prompts lose alignment with reality. Context becomes stale, and AI coding accuracy suffers.
Scaling context engineering requires automation and persistence. Context must be treated as an artifact that evolves alongside the codebase.
Signals Your Team Is Ready for Context Pipelines
Teams often experience clear warning signs before adopting context pipelines. These include repeated AI rework, inconsistent output quality, duplicated prompt templates, and growing skepticism toward AI tools.
When teams spend more time fixing AI output than reviewing it, the issue is rarely the model—it is missing operational context.
How Operational Context Improves AI Coding Accuracy
When context is prepared systematically, AI coding accuracy improves in predictable ways. Generated code aligns more closely with system intent, review cycles shorten, and trust in AI-assisted workflows increases.
Developers can focus on higher-level design and logic instead of correcting basic misunderstandings. AI becomes a reliable collaborator rather than a source of uncertainty.
Conclusion: Context Engineering Requires Infrastructure
Context engineering cannot remain an informal practice if teams expect consistent results. To deliver sustained value, it must be operationalized through pipelines and systems.
Moving from prompts to pipelines transforms AI-assisted development from an experiment into a dependable part of the engineering workflow. Teams that invest in operational context engineering unlock higher accuracy, lower rework, and greater confidence in AI coding agents.
Learn how we are tackling context engineering using Brunel, our AI Context Engineering Assistant