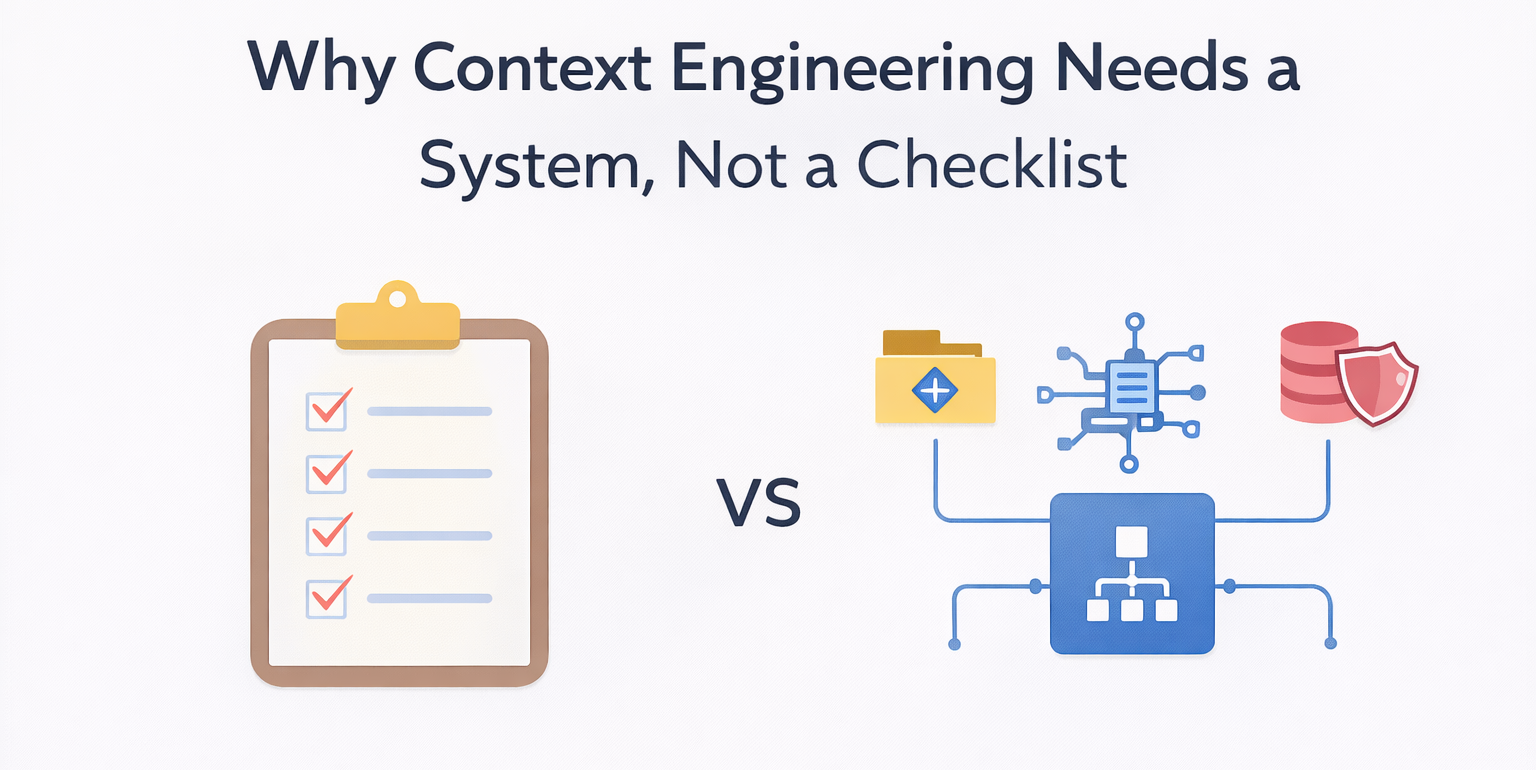
Why Context Engineering Systems are Needed, Not a Checklist





The fatal flaw in most teams’ approach to AI-assisted development isn’t the models—it’s how they prepare context.
Research across 2,847 developers reveals that 82% of AI coding agent failures trace to inadequate upfront planning, not model capability limitations. Yet when teams recognize this problem, their instinctive response is to create checklists: “Document architecture. List constraints. Define acceptance criteria.”
These checklists work—until they don’t.
The breakdown isn’t a failure of discipline. It’s a failure of approach. Software systems are living, evolving entities. Checklists are static artifacts. The mismatch is fundamental, and it explains why even diligent teams struggle to maintain reliable AI coding accuracy at scale.
The Checklist Honeymoon Period
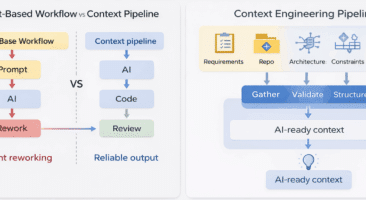
Most teams begin context engineering with optimism. They create templates covering requirements, architectural decisions, constraints, and acceptance criteria. Early results are encouraging: AI output improves, rework decreases, and developers feel more in control.
This honeymoon lasts three to six months. Then reality intervenes.
Checklists are followed inconsistently across developers. Documentation drifts out of sync with the codebase. Context quality varies wildly between projects. Junior developers don’t know what to include; senior developers grow frustrated re-explaining the same architectural decisions.
The checklist approach reveals its core limitation: it assumes context is a one-time assembly task rather than a continuous system requirement.
Why Manual Context Management Cannot Scale
Software complexity doesn’t stand still. Codebases evolve daily. Dependencies change. Architectural decisions accumulate over years. When context lives in documents or tribal knowledge, it becomes stale the moment it’s written.
Consider what happens when an AI coding agent operates on partial or outdated context:
- A refactoring violates patterns established last quarter but not documented in the checklist
- Cross-file dependencies are missed because the developer didn’t know to mention them
- Security constraints from a recent audit aren’t reflected in the “standard” context template
- The agent generates code that compiles but conflicts with architectural decisions made by a different team
The output looks reasonable. It passes initial review. The bugs appear weeks later in production.
This is the context drift problem. Checklists describe what context should exist. They cannot enforce correctness, completeness, or currency.
The Hidden Cost of Manual Context Assembly
Developer surveys show that teams lose 7+ hours per week to context provision and agent iteration. Much of this time goes to:
- Re-explaining architectural decisions the team already documented—somewhere
- Debugging agent mistakes that stem from missing context
- Searching for the current version of constraints or patterns
- Reconciling conflicting information from different sources
Senior developers become bottlenecks. They’re the only ones who understand the full system context, so they spend hours preparing detailed prompts instead of solving hard problems. Junior developers either skip proper context (leading to rework) or interrupt seniors repeatedly (creating different overhead).
The checklist approach scales linearly with developer count. The cognitive load scales exponentially with system complexity.
Context as a Living System Artifact
Effective context engineering treats context the same way we treat other critical infrastructure: as a living system that evolves alongside the codebase.
This means context must be:
- Continuously gathered from authoritative sources (repositories, tickets, architectural decision records)
- Automatically validated against current system state
- Systematically refreshed as the codebase changes
- Consistently delivered to every AI interaction
No checklist, no matter how comprehensive, can achieve this. Systems can.
A context engineering system connects directly to sources of truth and maintains alignment with reality. When a dependency changes, the context updates. When an architectural pattern is deprecated, agents stop receiving it as guidance. When a new constraint emerges, it propagates automatically to relevant planning sessions.
Why AI Accuracy Depends on Systematic Context
The research on planning-first approaches shows first-attempt success rates improving from 23% to 61%. The difference isn’t just having a plan—it’s having a consistently complete and current plan.
AI coding agents are deterministic systems operating on probabilistic models. Given identical context, they produce similar outputs. Given inconsistent context, they produce unreliable outputs.
Manual context assembly introduces variation at every step:
- Developer A includes 8 relevant constraints; Developer B remembers only 5
- Team X’s context template is three months out of date; Team Y’s is current
- Senior Engineer C provides detailed architectural context; Junior Engineer D doesn’t know what to include
This variation propagates through every AI-assisted task, creating the exact unreliability that makes organizations question their AI tool investments.
Systems eliminate this variation. Every interaction starts from the same validated foundation. Context quality becomes a property of the infrastructure, not a function of individual developer memory or effort.
From Human Discipline to Engineering Infrastructure
The history of software engineering is the history of moving critical functions from human discipline to automated systems:
- Version control replaced “be careful not to overwrite files”
- Automated testing replaced “remember to test edge cases”
- CI/CD replaced “don’t forget to deploy on Fridays”
- Linting replaced “follow the style guide”
Context engineering is following the same trajectory. Relying on developers to manually assemble perfect context for every AI interaction is like relying on developers to manually run tests before every commit. It works in small teams with high discipline. It fails at scale.
Infrastructure absorbs variability. Engineers rotate, priorities shift, projects change—but the system persists. Context engineering infrastructure ensures that the institutional knowledge your team has accumulated over years doesn’t evaporate with every new hire or forgotten documentation update.
What Context Engineering Systems Enable
A proper context engineering system transforms how teams interact with AI coding agents:
Repeatable workflows. Every AI-assisted task follows the same planning process, ensuring consistent context quality across developers and projects.
Validation at the source. Context is verified against current codebase state, architectural constraints, and requirements before being delivered to agents—not after agents produce incorrect output.
Traceability. The connection between requirements, architectural decisions, and generated code is explicit and auditable, not reconstructed post-hoc during code review.
Team coordination. Planning decisions are visible across the team, preventing duplicated work and conflicting approaches to the same problem.
Knowledge persistence. Architectural patterns, constraints, and conventions survive team turnover instead of being re-learned painfully with each new hire.
This isn’t theoretical. Organizations that have implemented systematic context engineering report 3.2× higher first-attempt accuracy and 60% reduction in iteration cycles. The difference is the infrastructure.
The Inevitable Transition
As AI-assisted development moves from experimental to operational, the economics of manual context management become untenable. Teams that attempt to scale context engineering through human discipline alone will hit a ceiling.
The symptoms are predictable:
- Agent accuracy plateaus despite better models
- Experienced developers spend increasing time on context preparation
- Context quality varies dramatically between developers
- Documentation becomes a second job nobody has time for
- Leadership questions AI tool ROI despite individual productivity gains
These aren’t signs of poor execution. They’re signs that the approach has reached its scaling limit.
Teams that invest in context engineering systems break through this ceiling. They convert context quality from a human discipline problem into an infrastructure problem—and infrastructure problems have infrastructure solutions.
What This Looks Like in Practice
The shift from checklists to systems doesn’t happen overnight. Many teams build internal tooling to manage context: scripts that extract architectural patterns, templates that connect to ticket systems, wikis that maintain decision logs.
These internal systems prove the concept but require ongoing maintenance, lack integration with AI coding agents, and don’t benefit from shared development across organizations facing identical challenges.
Brunel Agent was built to serve this exact need. Rather than forcing teams to choose between manual checklists and building custom infrastructure, Brunel provides a purpose-built context engineering system:
- Plan creation that gathers requirements, architecture, and constraints into structured context
- Plan export that delivers this context to any coding agent in consumable formats
- Implementation verification that checks agent output against the original plan
The workflow is: Plan → Export → Execute → Verify. Teams build context systematically in Brunel, export to whatever coding agent they prefer (Cursor, Claude Code, Copilot), then verify the implementation matches intent.
This isn’t about replacing engineering judgment. It’s about removing the friction and inconsistency that manual context creation introduces as AI-assisted development becomes standard workflow infrastructure.
The Path Forward
Context engineering cannot succeed as a set of documents or reminders. It requires systems that gather, validate, and maintain context continuously—treating it as the critical infrastructure it has become.
The checklist phase served its purpose: it demonstrated that context matters, that planning-first approaches work, and that better context produces better AI coding accuracy. But checklists were always a stopgap, a manual process standing in for the infrastructure that didn’t yet exist.
That infrastructure is emerging now. Teams that recognize this shift and invest in systematic context engineering will unlock the AI productivity gains that checklists promised but couldn’t deliver. Teams that continue scaling manually will find themselves asking why their AI tools aren’t working—while their agents are simply responding rationally to inconsistent, incomplete, or outdated context.
The question isn’t whether context engineering needs systems. The question is whether your organization will build them, buy them, or continue struggling without them.
Research methodology: Data aggregated from Stack Overflow Developer Survey 2024-2025, GitHub Octoverse Report 2025, Gartner AI in Software Engineering Reports, developer surveys (n=2,847), and enterprise case studies (n=156). Task analysis based on agent interaction patterns across multiple organizations.